需要的环境:正确配置的Python3.10+ ,一张可以使用CUDA的GPU(性能越强越好),Pycharm(推荐)
第一步:在Pycharm中创建虚拟环境/在Windows里面新建一个文件夹(没有pycharm)、
相信各位帅哥美女奶0帅t都会。
第二步:安装和你CUDA版本号适配的pytorch
- 打开CMD,输入nvidia-smi回车,你将看到以下界面
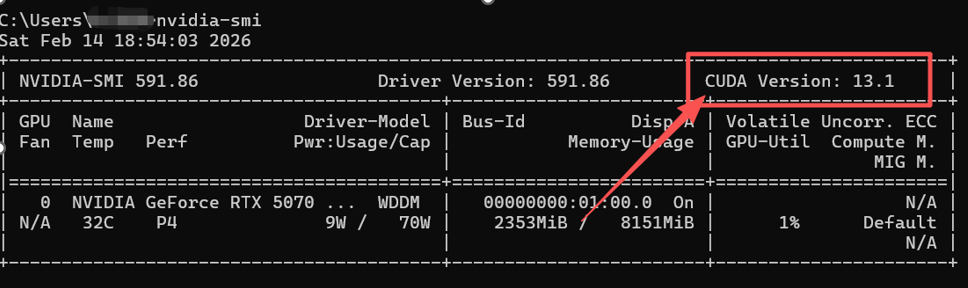
- 查看图片红框区域的CUDA版本号,记住它,然后打开https://pytorch.org/get-started/locally/,你将会看到以下界面

- 选择和你匹配的系统OS,Language选择Python,Compute Platform选择和你对应的CUDA版本即可,如果无独立GPU,请选择CPU,然后复制下面的Run this command部分
- 将Run this command部分粘贴到Pycharm的控制台里面(pycharm venv环境)或者直接粘贴到系统CMD里面(无pycharm),并且等待安装成功
- 验证torch安装状态:在项目中新建一个py文件,复制以下代码运行
如果输出为CUDA 是否可用: True,代表torch已经可以用CUDA加速
第三步:执行git clone https://github.com/jingyaogong/minimind.git,或者直接在minimind官网下载压缩包后解压,导入完成后执行pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple,下载外部依赖库
第四步:打开https://www.modelscope.cn/datasets/gongjy/minimind_dataset/files下载训练数据集,你应该至少需要一个pretraining数据集和sft监督微调数据集,这里推荐下载如下两个数据集
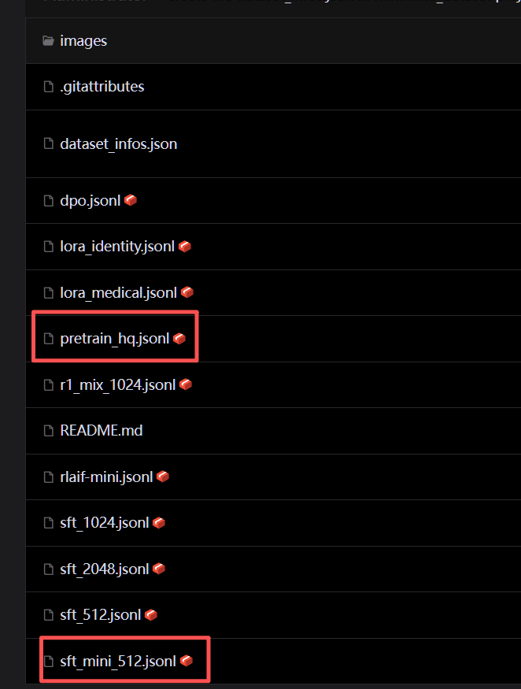
可以帮助你在短时间内构建出来一个基本能生成文字的LLM。下载这些数据集,并且把下载文件放到./dataset中即可(注:如果你下载的不是sft_mini_512,可能会出现需要改代码/修改文件名称才能激活微调的情况)
第五步:开始训练
首先cd trainer,然后执行train_pretrain.py,即可开始pretraining步骤。如果你使用的GPU性能不够强大,或者使用了纯CPU计算,此步骤需要消耗很长时间才能pretraining完成。
预训练完成后,我们需要进行SFT,这个步骤会让模型从一个知识渊博,但是不会说人话的LLM,变成一个能听懂并且回复人类的LLM,SFT的时间跟你的GPU算力和SFT文件大小有直接联系,我使用的RTX5070Laptop,使用sft_512.jsonl,花费了30小时才完成,sft_mini_512文件大约花费两三个小时即可完成,SFT完成后,你会在./out文件夹得到一个full_sft_XXX.pth文件,那就是最终你得到的轻量级LLM
第六步:测试
直接cd到项目根目录,然后python eval_llm.py –weight full_sft,即可测试你亲手训练的LLM效果啦
到这里,你已经成功的利用开源框架训练出来了自己的LLM,当然效果非常垃圾,如果各位帅哥美女们有更好的训练文件/更高算力的GPU集群,通过重新预训练/多次SFT,效果其实还不错,能达到基本日用水平。
哇呜,谢谢你呢